
티스토리 뷰
1. HTTP Connection
2. Connection Pool
3. MySQL 연동을 위한 Connection Pool 코드 구현
1. HTTP Connection
HTTP는 TCP 기반으로 만들어진 프로토콜이다. TCP는 신뢰성 연결을 지향하는 프로토콜로, 3-way Handshake를 통해 검증된 클라이언트와 서버 간에 신뢰성 있는 요청/응답이 가능하다.
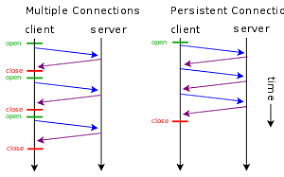
HTTP Connection에는 Multiple Connection과 Persistent Connection이 있다. HTTP 초기 버전에서는 Multiple Connection 방식을 사용했다. Multiple Connection은 매 요청/응답 쌍 마다 새로운 요청을 여는 것을 의미한다.
웹의 초창기에는 웹을 통해 전달해야 하는 사이트의 콘텐츠 수가 많지 않았기 때문에 다수의 TCP 연결 사용으로 인한 부담이 크지 않았지만, 웹 사이트의 콘텐츠(특히 이미지 등의 멀티미디어)가 늘어나면서 TCP 연결의 재사용이 필요하게 되었다. 클라이언트와 서버 간 요청/응답을 어떻게 하면 좀 더 빠르게 할 수 있을지에 대한 연구가 이루어졌고, 이때 나온 기술이 Persistent Connection 기술이다. Persistent Connection은 Keep-Alive 혹은 connection re-use라고 표현하기도 한다.
Persistent Connection은 하나의 TCP 연결을 사용하여 복수의 HTTP 요청/응답을 주고받는다는 개념이다. HTTP1.0기반에서 Persistent Connection 사용을 원하고, 이를 지원하는 클라이언트는 다음과 같이 서버에게 HTTP 요청을 할 때, 요청 헤더에 'Connection: keep-alive'라는 값이 담긴다.
HTTP1.1에서는 굳이 Connection 헤더를 사용하지 않아도 모든 요청과 응답이 기본적으로 Persistent Connection을 지원하도록 되어 있고, 이를 사용하지 않으려면 요청 헤더에 'Connection: Close'를 담으면 된다.
Persistent Connection을 사용하면서 얻을 수 있는 장점은 서버의 단일 시간 내 TCP 3-way Handshake 수를 최소화하여 서버의 CPU나 메모리 자원을 절약할 수 있고, 네트워크 혼잡이나 지연의 경우의 수를 줄일 수 있다. 또한, Persistent Connection은 복수 개의 HTTP 요청과 응답을 병렬적으로 동시에 처리하기 위한 HTTP Pipelining 기술을 사용하기 위해서는 꼭 지원되어야 한다.

항상 Persistent Connection을 쓰는 것이 좋을 것 같지만, 간혹 그렇지 않은 경우도 존재한다. 서버에 연결된 모든 클라이언트의 TCP 연결이 계속 늘어나다보면, 서버의 자원이 고갈되어 더욱 많은 클라이언트의 접속에 대처할 수 없는 상황이 발생할 수 있다. 따라서 클라이언트의 접속이 가장 많은 메인 페이지와 같은 URL에서는 서버의 가용성을 고려하여 Persistent Connection을 사용할지에 대해 고민해 볼 필요가 있다.

HTTP/2 버전은 멀티플렉싱(Multiplexing) 기능으로 단일 TCP 연결을 통해 다수의 요청/응답이 클라이언트와 서버 간에 응답지연(HOL: Header Of Line blocking) 없이 Stream 형태로 주고 받을 수 있는 기술적 토대가 만들어졌다. 따라서 HTTP/2를 사용하면 Persistent Connection에 대해 더 이상 고민할 필요가 없다.
2. Connection Pool
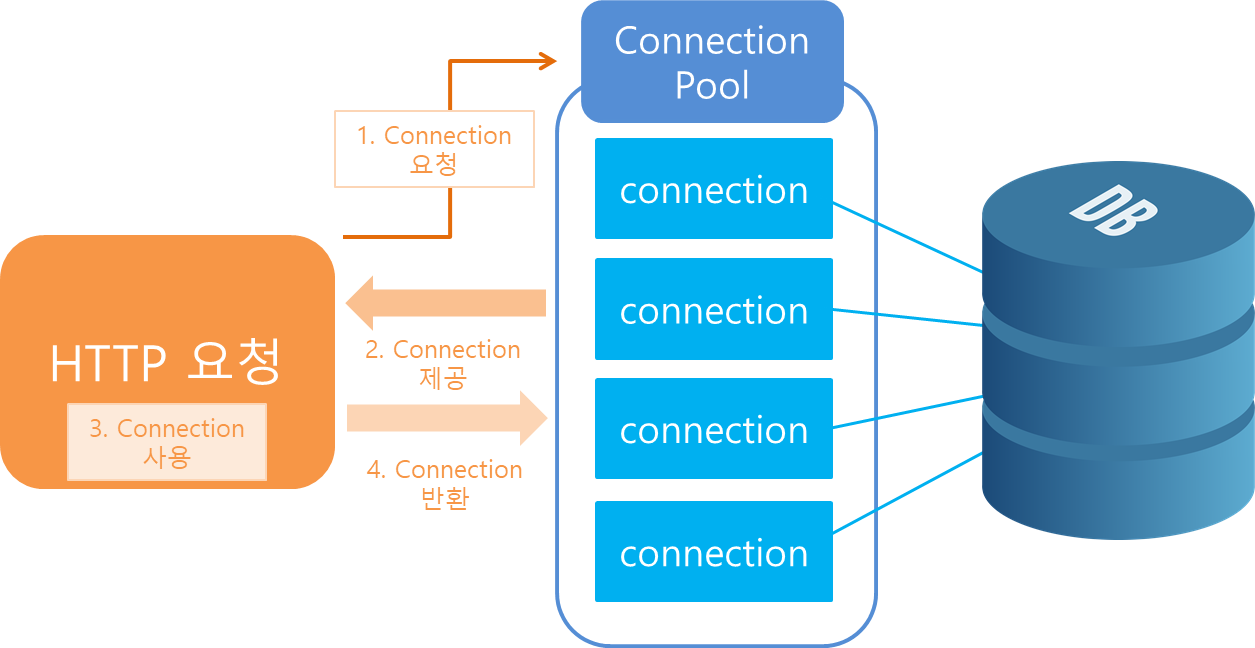
서버는 동시에 사용할 수 있는 사용자 수에 한계가 있다. 일반적인 Connection을 이용하면 동시 접속자 한계를 초과하게 될 경우 에러가 발생한다. 에러가 발생하면 그 접속자는 더이상 처리를 하지 못하므로, 웹 사이트 이용자는 재접속을 시도해야 하는 불편함이 발생한다. 이를 해결하기 위해 탄생한 것이 Connection Pool이다.
Connection Pool이란 동시 접속자가 가질 수 있는 Connection을 하나로 모아놓고 관리한다는 개념이다. 누군가 웹 사이트에 접속하면 자신이 관리하는 Pool에서 남아있는 Connection을 제공한다. 하지만 남아있는 Connection이 없는 경우에는 해당 클라이언트를 대기 상태로 전환시킨다. 그리고 Connection이 다시 Pool에 들어오면 대기 상태에 있는 클라이언트에게 순서대로 제공한다.
다시말해서 데이터베이스와 연결된 Connection을 미리 만들어서 Pool 속에 저장해 두고 있다가 필요할 때 Connection을 Pool에서 쓰고 다시 Pool에 반환하는 기법을 말한다.
Connection Pool 특징
- Pool 속에 미리 Connection이 생성되어 있기 때문에 Connection을 생성하는 데 드는 연결 시간이 소비되지 않는다.
- Connection을 계속해서 재사용하기 때문에 생성되는 Connection 수가 많지 않다.
- Connection Pool을 사용하면 Connection을 생성하고 닫는 시간이 소모되지 않기 때문에 그만큼 애플리케이션의 실행 속도가 빨라진다.
- 한 번에 생성될 수 있는 Connection 수를 제어하기 때문에 동시 접속자 수가 몰려도 웹 애플리케이션이 쉽게 다운되지 않는다.
3. MySQL 연동을 위한 Connection Pool 코드 구현
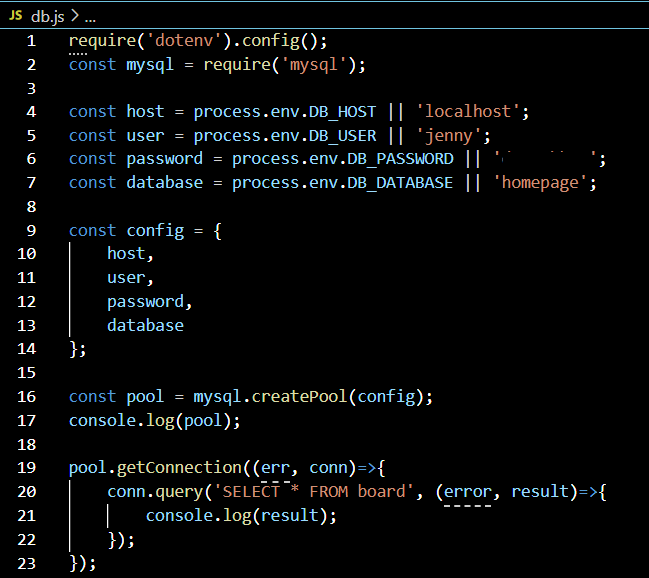
Node.js에서 MySQL과 연동하기 위해 Connection Pool 코드를 작성해주었다.
require()로 mysql 패키지를 불러오는 곳을 보면 알 수 있듯이 npm i mysql 명령어로 미리 설치해야 한다.
DB_HOST, DB_USER, DB_PASSWORD, DB_DATABASE는 .env라는 파일을 따로 만들어서 값을 지정해주었다.
변수 pool을 mysql 패키지의 createPool() 메소드에 config 객체를 넣은 것으로 정의했다. 쉽게 말해 새로운 Connection Pool을 생성하겠다는 의미이다.
getConnection() 메소드가 사용된 부분은 SQL문을 날려서 결과를 출력하는 부분이다. 위 코드에서는 SELECT문을 이용해서 board 테이블의 모든 필드를 보겠다는 것이고, error가 발생했을 때에 대해서는 따로 핸들링하지 않았다.
'Node.js' 카테고리의 다른 글
| [Node.js] nodemon, cookie-parser + chokidar (0) | 2022.03.03 |
|---|---|
| [Node.js] Crypto 모듈을 이용한 암호화, JWT (1) | 2022.03.02 |
| [Node.js] POST method의 content-type에 따른 body-parser (0) | 2022.02.17 |
| [Node.js] Router(라우터), Middleware(미들웨어) (0) | 2022.02.09 |
| Node.js를 이용한 로그인 기능 구현 (세션) (0) | 2022.02.08 |
- Total
- Today
- Yesterday
- 키워드
- Navigator 객체
- History 객체
- stdio.h
- long
- bom
- gcc
- Document Object Model
- window 객체
- 자료형
- int
- c언어
- Char
- short
- DOM
- 변수
- 컴파일
- Screen 객체
- location 객체
- keyword
- Browser Object Model
- 리액트 #React #props #state #javascript
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |